- Published on
How Stripe Ships 1,145 Pull Requests Per Day
- Authors

- Name
- Gabriel
- @gabriel__xyz
How Stripe Ships 1,145 Pull Requests Per Day (And How Your Team Can Too)
Picture this: While your team debates whether to ship that 500-line feature PR that's been in review for three days, Stripe's engineers have already merged 1,145 pull requests. Today. By the time you finish reading this guide, they'll have merged another 50.
Stripe processed $1.4 trillion in payments in 2024, serves millions of businesses across 120+ countries, and maintains 99.999% uptime. Yet somehow, they manage to merge an average of 1,145 pull requests every single day — a figure shared by CEO Patrick Collison at Stripe Sessions 2025.
The secret? It's not genius developers or unlimited resources. It's a systematic approach to engineering culture, tooling, and process optimization that any senior engineering team can adapt.
A note on this guide: The 1,145 PRs/day figure and high-level principles come from Stripe's public statements, engineering blog, and accounts from former engineers. The implementation examples throughout this guide are practical blueprints your team can use — not Stripe's exact internal configurations. Stripe uses custom infrastructure (Bazel, GitHub Enterprise Server, a massive Ruby monorepo) that wouldn't directly apply to most teams.
Here's your complete playbook.
The Three Pillars of High-Velocity Development
1. Organizational Structure & Culture
Small, Autonomous Teams with Clear Ownership
Stripe organizes around small teams of 5–8 engineers that own entire product areas: Payments Core, Identity, Climate, Terminal, etc. These teams work within Stripe's large Ruby monorepo (15M+ lines of code) with:
- Clearly owned sections of the codebase
- Independent deployment capabilities via feature flags
- Separate Slack channels and standups
- Clear API contracts with other teams
The Micro-PR Philosophy: Ship Features Like LEGO Blocks
Here's what a typical "feature" looks like broken down Stripe-style:
Traditional Approach (1 PR, 347 lines):
✗ Add user authentication with social login
- Add OAuth endpoints (127 lines)
- Create user model (45 lines)
- Build login UI (89 lines)
- Add session management (86 lines)
Stripe Approach (8 PRs, same feature):
✓ PR #1: Add user table schema (12 lines)
✓ PR #2: Create OAuth config constants (8 lines)
✓ PR #3: Add basic auth endpoint stub (15 lines)
✓ PR #4: Implement Google OAuth flow (34 lines)
✓ PR #5: Add user session utils (22 lines)
✓ PR #6: Create login component (41 lines)
✓ PR #7: Connect auth flow to UI (28 lines)
✓ PR #8: Add error handling (19 lines)
Each PR is reviewable in < 5 minutes. Each can be safely reverted. Each provides immediate value or foundation for the next step.
Continuous Delivery Mindset: Decouple Deploy from Release
// Instead of building entire features behind long-lived branches,
// use granular feature flags to decouple deploy from release
if (featureFlags.newOAuthFlow && user.betaAccess) {
return <NewOAuthComponent />
}
return <OldLoginComponent />
This allows merging incomplete work without affecting users. Features go live when they're ready, not when they're merged.
2. Developer Tooling & Automation (The Game Changer)
Lightning-Fast CI: The Sub-5-Minute Rule
Stripe targets sub-5-minute CI builds using Bazel with remote caching and execution. You can achieve similar speeds with parallelized GitHub Actions:
# Example optimized CI pipeline
name: Fast CI
on: [pull_request]
jobs:
test:
runs-on: ubuntu-latest
strategy:
matrix:
shard: [1, 2, 3, 4, 5, 6, 7, 8]
steps:
- uses: actions/checkout@v4
- uses: actions/cache@v4
with:
path: ~/.npm
key: ${{ runner.os }}-node-${{ hashFiles('package-lock.json') }}
- run: npm ci
- run: npm test -- --shard=${{ matrix.shard }}/8
Real Numbers:
- Traditional CI: 15-30 minutes
- Optimized CI: under 5 minutes
- Result: Engineers don't batch changes while waiting
Actionable Implementation:
- Parallelize everything: Split tests across 8+ runners
- Cache aggressively: Dependencies, build artifacts, test databases
- Run only affected tests: Use tools like Nx or Rush for monorepos
- Fail fast: Lint and type checks before expensive integration tests
Pre-merge Validation: Automation Does the Grunt Work
Instead of human reviewers catching syntax errors, automate the basics:
# .github/workflows/pr-checks.yml
- name: Type Check
run: tsc --noEmit
- name: Lint
run: eslint src/
- name: Unit Tests
run: jest --coverage
- name: Integration Tests
run: npm run test:integration
- name: Security Scan
run: npm audit
Human reviewers focus on:
- Business logic correctness
- Architecture decisions
- Performance implications
- Security considerations
Auto-merge: The Ultimate Velocity Multiplier
# .github/workflows/auto-merge.yml
name: Auto-merge
on:
pull_request_review:
types: [submitted]
jobs:
auto-merge:
if: github.event.review.state == 'approved'
runs-on: ubuntu-latest
steps:
- name: Enable auto-merge
run: gh pr merge --auto --squash
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
The --auto flag is key — it doesn't merge immediately. It waits until all your branch protection rules are satisfied:
- ✅ All required status checks pass
- ✅ At least 1 approval (or however many you require)
- ✅ No requested changes
- ✅ Up-to-date with main branch
Communication at Scale: Solving the Notification Problem
When you're shipping 100+ PRs daily, traditional notifications become noise. Here's the evolution:
Level 1: GitHub notifications (chaos)
- 47 emails per day
- Important PRs buried in noise
- Engineers disable notifications entirely
Level 2: Slack mentions (better, but manual)
👤 @channel: Please review my auth PR
👤 @sarah: Can you check the API changes?
👤 @team: Payment flow is ready for testing
The solution? Automate PR routing so notifications reach the right people without manual effort.
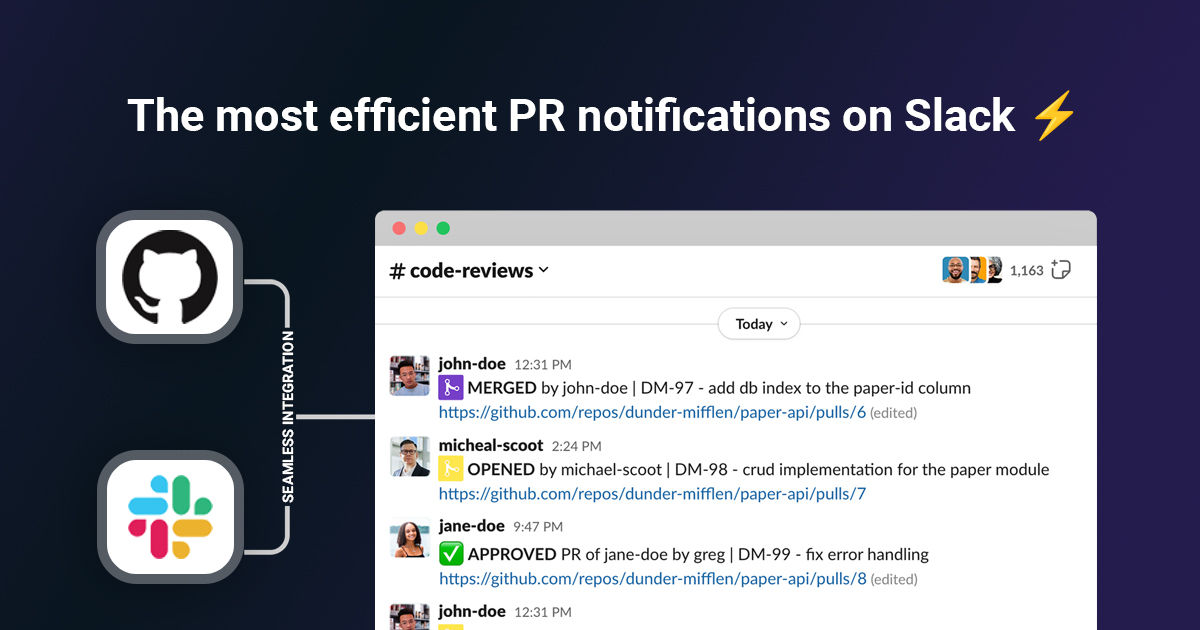
Level 3: Smart automation (PullNotifier approach)
🤖 Auto-routes PRs to relevant team channels
🤖 Notifies only required reviewers
🤖 Updates on status changes (approved/merged/closed)
🤖 Filters out draft/WIP PRs
The impact:
# Before: 5 minutes of manual coordination per PR (pinging reviewers, posting in channels)
# After: 0 minutes - automation handles routing and updates
# At 50 PRs/day: ~4 hours saved daily across the team
Independent Deployment Architecture
Whether you use a monorepo (like Stripe) or separate repos, the goal is the same: teams should be able to deploy without waiting on each other.
# Separate repos approach: each service deploys independently
payment-service/
├── .github/workflows/deploy.yml
├── Dockerfile
└── k8s/
dashboard-service/
├── .github/workflows/deploy.yml
├── Dockerfile
└── k8s/
# No waiting for other teams' deployments
git push origin main # Auto-deploys payment-service
# Dashboard team can deploy whenever they're ready
3. Safety Nets That Enable Speed
Feature Flags: The Confidence Multiplier
Stripe deploys risky changes safely by hiding them behind granular controls. Former engineers have described a sophisticated system of "flags" (for rollouts) and "gates" (for deprecated behaviors) that supports per-account targeting, percentage-based rollouts, and kill switches. Here's a simplified version of this pattern:
// Simple feature flagging system
const featureFlags = {
newPaymentFlow: {
enabled: true,
rollout: 0.05, // 5% of users
segments: ['beta_users', 'stripe_employees']
},
enhancedSecurity: {
enabled: true,
rollout: 1.0, // 100% rollout
killSwitch: false
}
}
// In your component
function PaymentPage() {
const flags = useFeatureFlags()
if (flags.newPaymentFlow) {
return <NewPaymentComponent />
}
return <LegacyPaymentComponent />
}
Real Example: Deploying a Redesigned Checkout
Week 1: Deploy to 1% of traffic (behind flag)
Week 2: Monitor metrics, increase to 10%
Week 3: Full rollout to 100%
All while merging other features daily
Instant Rollback: Fail Fast, Recover Faster
# Feature flag rollback (instant)
curl -X POST api/admin/flags \
-d '{"newPaymentFlow": {"enabled": false}}'
# Code rollback (< 2 minutes)
git revert abc123
git push origin main
# Auto-deploys reverted version
# Database rollback (rare, but planned)
kubectl apply -f rollback-migration.yml
Comprehensive Observability: Know Before Your Users Do
// Automatic error tracking
try {
await processPayment(amount)
metrics.increment('payment.success')
} catch (error) {
metrics.increment('payment.error')
logger.error('Payment failed', {
error,
userId,
amount,
featureFlags: getCurrentFlags()
})
// Auto-alert if error rate > 1%
}
Monitoring Dashboard Examples:
- Real-time error rates per feature flag
- Performance metrics (p95 response times)
- Business metrics (conversion rates, revenue)
- Deployment frequency and success rates
Your 30-Day Implementation Guide
Week 1: Audit & Foundation
Day 1-2: Measure Current State
# Audit your current PR metrics
gh pr list --state=merged --limit=100 \
--json=number,createdAt,mergedAt,additions,deletions
# Calculate average:
# - PR size (lines changed)
# - Time to merge
# - Review cycles per PR
Day 3-5: Set Up Basic Automation
# .github/workflows/fast-feedback.yml
name: Fast Feedback
on: [pull_request]
jobs:
quick-checks:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Lint (fail fast)
run: npm run lint
- name: Type check (fail fast)
run: npm run type-check
- name: Unit tests (parallel)
run: npm run test:unit -- --maxWorkers=4
Day 6-7: Team Training Workshop
- Exercise: Take a real feature and break it into 5+ micro-PRs
- Practice: Feature flag implementation patterns
- Demo: Show auto-merge workflow
Week 2: Implement Micro-PR Culture
Practice Breaking Down PRs
❌ Bad: "Add shopping cart feature" (247 lines)
✅ Good: Break it down:
1. "Add cart data model" (12 lines)
2. "Create cart API endpoints" (34 lines)
3. "Add cart context provider" (28 lines)
4. "Build cart UI components" (41 lines)
5. "Connect cart to checkout" (19 lines)
6. "Add cart persistence" (23 lines)
PR Size Guidelines:
- 🟢 0-50 lines: Perfect
- 🟡 51-150 lines: Good
- 🟠 151-300 lines: Needs justification
- 🔴 300+ lines: Break it down
Set Up PR Templates
## PR Type
- [ ] Bug fix
- [ ] Feature (broken into smallest possible increment)
- [ ] Refactor
- [ ] Documentation
## Checklist
- [ ] < 150 lines of changes
- [ ] Has automated tests
- [ ] Feature flagged if user-facing
- [ ] Can be safely reverted
Week 3: Optimize CI/CD Pipeline
Parallelize Your Tests
# Before: 15 minutes sequential
test:
runs-on: ubuntu-latest
steps:
- run: npm run lint # 2 min
- run: npm run test:unit # 8 min
- run: npm run test:e2e # 5 min
# After: 5 minutes parallel
test:
runs-on: ubuntu-latest
strategy:
matrix:
task: [lint, test:unit, test:e2e]
steps:
- run: npm run ${{ matrix.task }}
Set Up Auto-merge
# Enable auto-merge on repo
gh repo edit --enable-auto-merge
# Create auto-merge rule
gh api repos/:owner/:repo/rulesets \
--method POST \
--field name="Auto-merge approved PRs" \
--field target="branch" \
--field enforcement="active"
Week 4: Communication & Safety Nets
Implement Smart Notifications
Option 1: GitHub Actions notification
- name: Notify team
uses: 8398a7/action-slack@v4
with:
status: ${{ job.status }}
channel: '#engineering'
text: 'PR ready for review: ${{ github.event.pull_request.html_url }}'
Option 2: Use PullNotifier for advanced routing
- Auto-routes to relevant team channels
- Filters noise (drafts, WIP, etc.)
- Updates on status changes
- Zero manual configuration
Basic Feature Flagging
// config/features.js
export const features = {
newCheckout: process.env.FEATURE_NEW_CHECKOUT === 'true',
advancedSearch: process.env.FEATURE_ADVANCED_SEARCH === 'true'
}
// components/Checkout.js
import { features } from '../config/features'
export function Checkout() {
if (features.newCheckout) {
return <NewCheckout />
}
return <LegacyCheckout />
}
Measuring Success: KPIs That Matter
Track these metrics to measure your high-velocity transformation:
Velocity Metrics:
- PRs merged per day (target: 2-5x increase)
- Average PR size (target: < 100 lines)
- Time to merge (target: < 4 hours)
Quality Metrics:
- Bug reports per 100 PRs (should stay flat or improve)
- Rollback frequency (should stay low)
- CI success rate (target: > 95%)
Team Health:
- Developer satisfaction scores
- Time spent on PR coordination (should decrease)
- Feature delivery velocity (should increase)
Common Pitfalls & How to Avoid Them
Pitfall #1: "Our PRs are too complex to break down"
❌ "This payment refactor touches 47 files, can't be smaller"
✅ Break by layers:
1. Add new interfaces (no implementation)
2. Implement core logic (behind feature flag)
3. Update API endpoints (one at a time)
4. Migrate frontend components (one by one)
5. Remove old code (separate PR)
Pitfall #2: "Auto-merge will break production" Start conservative, evolve trust:
# Week 1: Auto-merge docs only (use a paths filter action)
- uses: dorny/paths-filter@v3
id: changes
with:
filters: |
docs:
- '**/*.md'
- if: steps.changes.outputs.docs == 'true'
run: gh pr merge --auto --squash
# Week 2: Auto-merge small PRs (under 50 lines added)
- if: github.event.pull_request.additions < 50
run: gh pr merge --auto --squash
# Week 3: Auto-merge all approved PRs
- if: github.event.review.state == 'approved'
run: gh pr merge --auto --squash
Pitfall #3: "Too many notifications will overwhelm the team" Smart routing solves this:
Frontend PRs → #frontend-team
API changes → #backend-team
Docs changes → #docs-team
Security PRs → #security + #leads
What Realistic Results Look Like
Here's a hypothetical but grounded example of what these changes can do for a mid-size team (50 engineers):
Typical starting point:
- ~12 PRs/day, 3–5 day average merge time, 30+ min CI
After 90 days of implementing this playbook:
- 40–50 PRs/day, under 8 hours average merge time
- Faster feature delivery with fewer production incidents
Suggested implementation timeline:
- Month 1: CI optimization (get builds under 10 minutes)
- Month 2: Micro-PR training + auto-merge setup
- Month 3: Smart notifications + feature flags
The Bottom Line: It's About Sustainable Speed
Stripe's 1,145 daily PRs isn't a sprint—it's a marathon pace they've maintained for years. The secret isn't heroic effort; it's systematic process optimization.
The math is simple:
- Traditional team: 10 engineers × 1 PR every 3 days = 3.3 PRs/day
- Stripe-style team: 10 engineers × 2-3 micro-PRs daily = 25 PRs/day
The difference maker:
- Cultural shift: Big features → small increments
- Tool investment: Manual coordination → automated workflows
- Safety nets: Fear-driven delays → confident rapid iteration
Your transformation starts today:
- Pick one feature currently in development
- Break it into 5+ micro-PRs
- Ship the first one this afternoon
- Measure the difference in review speed and confidence
The companies that master this approach — Stripe, GitHub, Shopify — don't just ship faster. They ship better software with happier engineering teams and more predictable delivery timelines.
Ready to 10x your team's velocity? Start with PullNotifier to eliminate communication friction, then implement the systematic changes outlined in this guide. Your future self (and your users) will thank you.
Sources: Stripe Sessions 2025 Opening Keynote, Stripe 2024 Annual Update, Stripe Engineering Blog, Brandur Leach on Stripe's feature flags, Nelson Elhage on Stripe's dev environment.