- Published on
Mastering change failure rate: Diagnosis & Reduction
- Authors

- Name
- Gabriel
- @gabriel__xyz
Change failure rate (CFR) is the percentage of your production deployments that blow up and force an immediate fix, like a hotfix or a full rollback. It’s one of the core DORA metrics and it’s all about measuring the stability and quality of your software delivery—not just how fast you can ship.
A low CFR is a sign of a healthy, reliable engineering process.
What Is Change Failure Rate and Why It Matters
Picture your development pipeline as a high-speed assembly line. Every deployment is a brand-new car rolling out to customers. Your change failure rate is simply the percentage of those cars that have a critical defect and need to be recalled right off the lot.
We're not talking about minor scratches found weeks later; we're talking about the engine falling out as soon as the customer turns the key.
This metric gives you a direct, unfiltered look at the health of your delivery engine. It goes beyond just counting bugs and gets straight to the real-world impact of your changes. A high CFR is a massive red flag that something in your process is broken, whether it’s your code quality, testing, or deployment strategy. It screams instability and risk.
More Than Just a Number
Tracking your change failure rate is a big deal because it ties directly to business outcomes and team sanity. A consistently low rate isn't just a nice-to-have technical achievement; it's the foundation for building something great.
Here’s why it’s so critical:
* **Builds Customer Trust:** Every time a user runs into a failed deployment, you chip away at their confidence in your product. A low CFR translates to a stable, dependable service that keeps customers happy and sticking around.
* **Improves Developer Morale:** Nobody enjoys constantly fighting fires and rolling back broken code. It’s exhausting and demoralizing. A stable process lets your engineers focus on building cool new features instead of cleaning up yesterday's messes.
* **Reduces Unplanned Work:** Each failure kicks off a fire drill of unplanned work—hotfixes, emergency patches, and soul-crushing post-mortems. Cutting down your CFR frees up a ton of time and energy for work that actually moves the needle.
A high change failure rate means you’re constantly dealing with self-inflicted wounds that disrupt the entire team. A low rate suggests a well-oiled machine with far fewer interruptions.
Benchmarking Your Performance
So, how does your team stack up? The DevOps world generally groups CFR performance into a few distinct tiers. This chart gives you a visual breakdown of where most teams land.
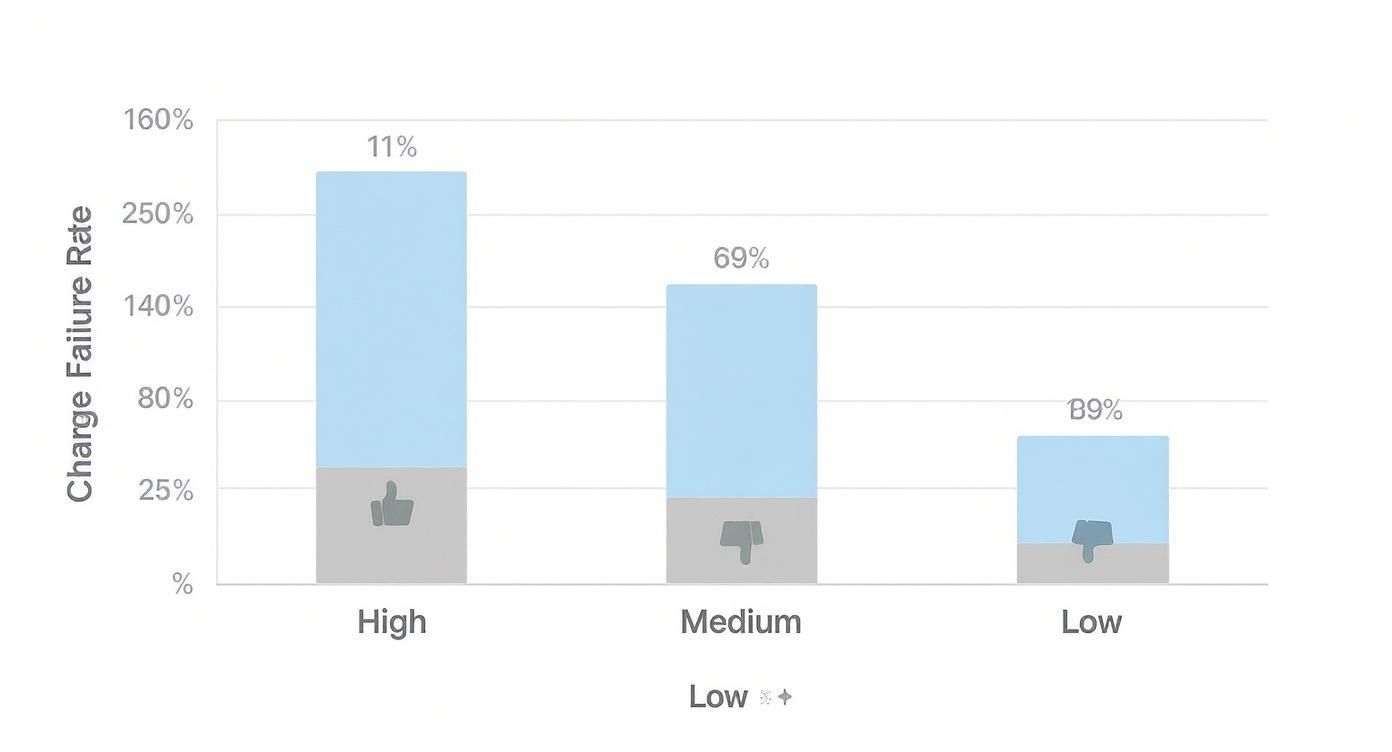
That data tells a pretty clear story: a whopping 69% of organizations are stuck in the "medium" performer category. Only a small fraction actually reaches elite status.
To put some hard numbers on it, the 2022 State of DevOps Report from DORA offers a useful guide for benchmarking your performance.
Change Failure Rate Performance Benchmarks
This table breaks down the performance tiers, helping you see where you stand and what to aim for.
| Performance Tier | CFR Percentage Range | Typical Characteristics |
|---|---|---|
| Elite | 0-5% | Highly automated pipelines, small and frequent deployments, comprehensive testing. |
| High | 6-15% | Strong CI/CD practices, good test coverage, and a proactive approach to quality. |
| Medium | 16-30% | Some automation in place but manual steps remain; inconsistent testing practices. |
| Low | 31% or higher | Manual, infrequent deployments; testing is often an afterthought. Failures are common. |
Elite and high-performing teams consistently maintain a CFR between 0-15%. They get there by leaning heavily on practices like extensive test automation and shipping small, incremental changes, which makes it way easier to spot and fix problems before they can cause a major outage.
Ultimately, CFR is a vital piece of a much larger puzzle. For a deeper dive into how it fits with other key indicators, check out our guide to engineering productivity measurement. When you measure what matters, you empower your team to pinpoint weaknesses and build more resilient systems.
Diagnosing the Root Causes of a High CFR
Knowing your change failure rate is a lot like seeing the "check engine" light pop up on your dashboard. It’s a clear signal that something is wrong, but it doesn't tell you what or why. To really fix the problem, you have to look past the symptom—the failed deployment—and dig into the root causes hidden deep within your software delivery process.

A high CFR is rarely caused by a single, isolated issue. It's usually the result of a tangled mess of process gaps, technical debt, and team culture that, together, create the perfect storm for failure. By pulling these threads apart, you can start to see where the real cracks are.
Inadequate or Brittle Testing Strategies
The most common culprit behind a high change failure rate is, without a doubt, a weak testing strategy. When testing gets rushed, is incomplete, or relies too heavily on manual checks, it's almost guaranteed that bugs will find their way into production.
This problem usually shows up in a few key ways:
* **Lack of Automation:** Teams still leaning on manual testing just can't keep pace. Automated tests are your first and best line of defense, catching regressions and obvious errors long before they ever get near a staging environment.
* **Poor Test Coverage:** You might have automation, but are you testing the right things? Gaps in your unit, integration, and end-to-end tests leave critical user journeys completely exposed.
* **Environment Mismatch:** When your staging environment is a distant cousin of production, tests can pass with flying colors locally only to explode on deployment. That classic "it worked on my machine" moment is a dead giveaway of environment drift.
A high CFR is often a lagging indicator of a poor testing culture. By the time a failure happens in production, the real mistake was made much earlier in the pipeline when a critical test was skipped, poorly written, or never created at all.
Risky Deployment and Integration Practices
Even with flawless code, how you merge and deploy your changes can introduce a massive amount of risk. Many teams are stuck with integration habits that make failures not just more likely, but also a nightmare to debug when they inevitably happen.
One of the biggest offenders is the "big bang" release. This is what happens when teams camp out on long-lived feature branches for weeks (or even months), culminating in a huge, complex merge. Trying to integrate dozens of changes all at once creates a chaotic mess where it's nearly impossible to figure out which specific change broke everything.
Another major risk is relying on manual steps to get code to production. Every manual action—running a script, tweaking a server config, updating a database—is a golden opportunity for human error. One forgotten step or a simple typo can easily bring down the entire system, turning a routine deployment into an all-night fire drill.
Cultural and Communication Breakdowns
At the end of the day, technology and processes are only half the picture. A high change failure rate can also be a symptom of deeper cultural problems within a team or organization. These human factors are often the hardest to spot, but they can have the most devastating impact.
Keep an eye out for these common cultural blockers:
* **Siloed Teams:** When development, QA, and operations teams don't really talk to each other, critical information gets lost in translation. Devs might push a change, completely unaware of an infrastructure update Ops is planning, leading to failures that were 100% preventable.
* **Fear of Speaking Up:** In a culture that penalizes mistakes, engineers are much less likely to raise a red flag about a risky change or point out a flaw during a code review. This fear creates dangerous blind spots that only become obvious after a production incident.
* **Pressure to Ship at All Costs:** When hitting deadlines consistently trumps shipping quality code, teams are forced to cut corners. That means skipping tests, rushing code reviews, and pushing out changes they don't fully understand. In that environment, a high CFR isn't just possible—it's practically inevitable.
Here are some practical ways you can start chipping away at your Change Failure Rate.
Figuring out why your Change Failure Rate is high is one thing; fixing it is another. There's no single silver bullet here. Lowering your CFR for good means taking a hard look at your processes, your team culture, and the tech you use every day.
Think of these strategies less as quick fixes and more as foundational shifts. You're building resilience directly into the way you ship software. The goal is to move from a reactive state of constant firefighting to a proactive one where quality is baked in from the start. Each of these tactics is a concrete step toward making deployments safer and a whole lot less stressful.
Refine Your Development and Deployment Processes
The way your team builds and ships code has a massive, immediate impact on your CFR. If your processes are complicated, manual, or happen infrequently, you’re basically creating a breeding ground for errors. Streamlining these core workflows is the most powerful lever you can pull.
A great place to start is by ditching long-lived feature branches. When developers work in isolation for weeks at a time, the final merge becomes a chaotic, high-stakes event. Instead, give trunk-based development a shot. Everyone commits small changes to a single main branch, which forces frequent integration and makes it way easier to spot issues before they blow up.
This naturally leads to another game-changing practice: shipping in small batches. It’s just common sense. Deploying a single, tiny change is fundamentally less risky than a monster release with hundreds of commits. If something breaks, the problem is contained, and the rollback is simple.
A small change that fails is a minor headache you can fix in minutes. A huge release that fails is a full-blown crisis that can take down your system for hours.
Foster a Culture of Blameless Learning
Your team’s culture is just as important as any process or tool. A high-blame, high-pressure environment just encourages developers to hide mistakes or cut corners—which, surprise, leads to more failures. To really move the needle on your CFR, you have to build a culture of psychological safety where the main goal is to learn, not to point fingers.
It all starts with how you handle incidents. When a deployment goes wrong, the goal shouldn't be to find out who to blame. It should be to understand why the system allowed the failure to happen in the first place. That’s the heart of a blameless post-mortem. The conversation shifts from "Who pushed the bad code?" to "What can we change in our process to make sure this kind of error can never happen again?"
This cultural shift is a big deal. Interestingly, this isn't just a software problem. Research across all industries shows that organizational change initiatives fail at a shocking rate, often due to employee resistance. Investing in a supportive culture pays off—organizations that focus on culture see 5.3x higher success rates in their initiatives than those that just throw technology at the problem. You can dig into more change management statistics that highlight these patterns on Pollack Peacebuilding's blog.
Leverage Modern Technology and Automation
Last but not least, your tech stack can either be your safety net or a minefield. The right tools and automation can wipe out entire categories of human error, enforce best practices, and give you the visibility you need to deploy with confidence. For any team serious about lowering its CFR, a modern CI/CD pipeline is absolutely non-negotiable.
Here are the key pieces of tech you should have in place:
* **Robust Automated Testing:** Your CI pipeline should be your first line of defense, automatically running a full suite of tests—unit, integration, end-to-end—on every single commit. This is how you catch regressions before they ever get near a human reviewer.
* **Infrastructure as Code (IaC):** Using tools like [Terraform](https://www.terraform.io/) or [Pulumi](https://www.pulumi.com/), you can define and manage your infrastructure in code. This gets rid of environment drift between staging and production, a classic source of "but it worked on my machine" deployment failures.
* **Feature Flags:** Think of these as on/off switches for new code. They let you deploy changes to production in a "disabled" state, then slowly turn them on for a small group of users. This completely de-risks the release process. If the new feature causes problems, you just flip the switch off—no emergency rollback needed.
* **Progressive Rollouts:** Strategies like canary releases or blue-green deployments let you gradually shift traffic over to the new version of your application. This minimizes the blast radius of a potential failure, since only a small percentage of users are ever exposed to the new code before you can safely roll back.
Nail Your Code Review and Quality Gates

Think of your code review process as the most important quality gate you have. It's your best chance to catch problems long before they ever get a chance to wreak havoc in production. This isn't just about ticking a box; it's a collaborative effort that sharpens code quality, spreads knowledge, and ultimately drives down your change failure rate.
But let's be honest—a clunky, poorly-run review process can cause more headaches than it solves, creating bottlenecks and friction. The real goal is to turn it into a lean, proactive checkpoint that stops bad code dead in its tracks.
It all starts with how code is even presented for review. We’ve all seen them: those massive, sprawling pull requests (PRs) that touch dozens of files. They are nearly impossible to review with any real focus. They practically beg for skim-reading and rubber-stamping, which is exactly how subtle—but critical—bugs slip through the cracks.
Building a Better Review Process
The bedrock of any solid review culture is the small, focused pull request. Each PR should be a single, logical chunk of work that a reviewer can actually wrap their head around. This simple shift makes it dramatically easier to spot errors and understand the "why" behind the change.
To get there, your team needs to agree on what a "good" PR looks like. This usually includes:
* **A Clear and Descriptive Title:** It should explain *what* the change does in a single glance.
* **A Detailed Description:** The body needs to cover the *why*, linking out to tickets or design docs for context.
* **Limited Scope:** A PR should only make significant changes to a handful of files. If a feature is too big, it needs to be broken down into smaller, self-contained PRs first.
Think of a code review like editing a book. Reviewing a single, well-written paragraph is manageable and effective. Trying to edit an entire unstructured chapter in one sitting is a recipe for missing crucial errors.
By enforcing smaller batch sizes at the review stage, you directly lower the risk of every single merge. This has a massive downstream effect on your change failure rate.
Integrating Automation and Checklists
Even the most meticulous human reviewers are, well, human. We miss things. That’s where automation and simple checklists come in, acting as a consistent safety net.
Automated tools are your first line of defense. By integrating static analyzers and linters directly into your CI pipeline, you can automatically flag common mistakes, style issues, and potential bugs before a PR ever lands in a reviewer's queue. This saves everyone a ton of time on the low-hanging fruit, freeing up human reviewers to focus on the tricky stuff—like business logic and architectural design.
Beyond the robots, a straightforward checklist can do wonders for consistency. It formalizes the review process, making sure common oversights are a thing of the past. For a great starting point, you can adapt a pre-built code review checklist to fit your team's specific stack and workflow. It ensures every reviewer is asking the same critical questions.
To level up your process even further, explore these best practices for code review for more strategies on shipping faster without sacrificing quality. Combining these structured approaches creates a multi-layered defense that dramatically reduces the chances of shipping faulty code.
Using Automation and Tooling to Drive Down Failures
Strong processes and a healthy culture are the bedrock of a low change failure rate, but they can only take you so far. To truly scale, you need the right technology. Manual steps are where human error, inconsistency, and slowdowns creep in. Automation and strategic tooling act as your engineering team's ultimate safety net, enforcing best practices and catching problems long before they can affect users.
Good tools don't just make you faster; they make your entire software delivery lifecycle more reliable and predictable. By systematically taking manual work out of the equation, you eliminate entire categories of potential failures.
Automating Your Delivery Pipeline
The engine of modern software delivery is the Continuous Integration and Continuous Deployment (CI/CD) pipeline. Platforms like GitHub Actions, GitLab CI, or Jenkins are designed to automate the entire journey from code commit to deployment. This isn't just about convenience—it's a powerful quality control mechanism.
Every single time a developer pushes code, a well-configured CI/CD pipeline should kick off and automatically:
* **Run a comprehensive test suite:** This should cover everything from unit and integration tests to end-to-end tests, giving you immediate feedback on whether a change broke something.
* **Perform static code analysis:** Tools scan the code for common bugs, security vulnerabilities, and style violations, catching the low-hanging fruit without any human effort.
* **Build and package the application:** This creates a consistent, repeatable build process every single time, finally putting the "it worked on my machine" problem to rest.
This level of automation creates an incredibly tight feedback loop. Issues are flagged within minutes of being introduced, not days or weeks later during a stressful, last-minute scramble before a release.
Closing the Communication Loop with Smart Tooling
Beyond the pipeline, the right tools can fix one of the biggest silent killers of velocity and quality: communication gaps. The code review process, in particular, often turns into a bottleneck where pull requests (PRs) sit idle, waiting for a reviewer to notice them. This delay is risky—the longer a PR waits, the more likely it is to conflict with other changes, becoming stale and dangerous to deploy.
This is where specialized tools really shine. They bridge the gap between your git repository and your team's communication hub, making sure nothing falls through the cracks. For example, a tool like PullNotifier provides real-time, consolidated alerts for PRs and build statuses directly in Slack.
Here’s a look at how PullNotifier keeps a team in the loop without creating a firehose of notifications.
This clean, threaded view lets every stakeholder see the status of a PR at a glance—from creation and review to approval and deployment.
That immediate visibility is a game-changer. When reviewers get notified instantly and contextually, review times plummet. Faster reviews mean code gets merged quicker, drastically reducing the chances of it becoming outdated. This tightens the entire development cycle, directly lowering your change failure rate by preventing stale, conflict-ridden code from ever making it to production. For teams looking to nail this critical step, our guide on automating code review with smarter tools offers a practical roadmap.
Gaining Insight with Observability
Once your code is deployed, a new set of tools becomes essential. Observability platforms like Datadog or New Relic give you deep insight into how your application is actually behaving in production. They go beyond simple monitoring to help you understand the why behind any problem.
By tracking metrics, logs, and traces, these tools can immediately alert you to anomalies that might indicate a failed change—often before your customers even notice something is wrong. This allows for rapid diagnosis and rollback, turning a potential outage into a minor blip. Pairing a strong CI/CD pipeline with robust observability tools creates an end-to-end system that not only prevents failures but also minimizes their impact when they inevitably happen.
Connecting Technical Excellence to Business Strategy

Let's be clear: a low change failure rate is much more than a technical vanity metric. It’s a direct pulse on your business’s health and ability to adapt. When your engineering teams can ship changes with confidence, the entire organization breathes a sigh of relief. It builds the trust needed to innovate, react to market shifts, and deliver real value to customers, faster.
On the flip side, a high CFR is often a symptom of deeper, systemic business issues. Maybe it's a C-suite strategy that’s out of sync with engineering reality, or intense pressure to prioritize speed above all else. This kind of environment forces teams into a miserable cycle: ship code, then immediately fix it. You burn out your best people and chip away at customer trust with every failed deployment.
The Strategic Impact of Stable Deployments
True digital transformation isn’t about buying flashy new tools. It's about building an organization that can withstand pressure and keep moving forward. When your deployments are stable and predictable, the business reaps some serious rewards:
* **Predictable Value Delivery:** Marketing can launch campaigns with confidence. Sales can close deals without worrying the platform will fall over. Everyone trusts that the product will just *work*.
* **Reduced Operational Waste:** Fewer failures mean your team spends less time on frantic, late-night hotfixes. That time can be reinvested into building new, revenue-generating features instead.
* **Enhanced Innovation Capacity:** Teams that aren't constantly putting out fires have the mental space and technical bandwidth to get creative, experiment, and solve bigger problems for your customers.
But this is exactly where so many transformation efforts fall flat—they ignore the critical link between technical stability and business outcomes. Despite huge investments, global digital transformation initiatives see only a 35% success rate in hitting their value targets. A big reason for this is bad data, which 64% of organizations name as their top challenge, costing them millions each year. You can dig deeper into these numbers with these data transformation challenge statistics on Integrate.io.
Achieving elite performance is not just about fixing bugs. It's about creating a system where technical stability and strategic goals are perfectly aligned, allowing quality and speed to become two sides of the same coin.
At the end of the day, a low change failure rate tells a powerful story. It signals that your organization has evolved beyond just writing code and is now running a robust, predictable, value-delivery engine.
Common Questions About Change Failure Rate
As your team starts paying closer attention to its change failure rate, a few questions always pop up. Getting clear, consistent answers is the first step to measuring this metric accurately and actually using it to drive improvements. Let’s tackle some of the most common ones.
What Counts as a Failure for CFR?
Simply put, a "failure" is any change that hits production, degrades the service, and forces you to scramble for an immediate fix. This isn't about minor bugs you find a week later; it's about incidents that demand an urgent, unplanned response to get things stable for your users again.
This kind of firefighting can take a few different forms:
* **A hotfix** to patch the problem directly in production.
* **A full rollback** to yank the problematic change.
* **A "fix-forward"** where a new patch is deployed right away to correct the error.
The key ingredient here is urgency. The fix is an unplanned reaction to a deployment that broke something. Your team has to agree on this definition so everyone tracks failures the same way, otherwise the metric becomes meaningless.
How Often Should We Track Our CFR?
While you calculate change failure rate from every single deployment, its real value comes from watching the trend over time. Freaking out over the result of one or two deployments is a great way to cause unnecessary panic.
Instead, track it continuously but review it as a team on a regular cadence, like weekly or bi-weekly. This smooths out the day-to-day noise and gives you a much more reliable signal of your delivery health. It’s all about spotting meaningful patterns, not overreacting to tiny blips.
Is a 0% Change Failure Rate a Good Goal?
Chasing a 0% CFR sounds great in theory, but it's often a trap. Sure, a team might hit it for a short stretch, but a consistently zero failure rate can be a red flag. It might mean your team isn't deploying often enough or is shying away from the smart risks needed for innovation.
The goal isn't absolute, unachievable perfection. It’s about achieving a sustainably low rate. For high-performing teams, the benchmark is under 15%. This shows you have a resilient and mature delivery process that doesn't bring progress to a grinding halt.
Stop letting pull requests get lost in the noise. PullNotifier delivers clean, real-time PR and build updates directly to Slack, cutting through the clutter so your team can review and merge code faster. Reduce your review delays and tighten your development cycle at https://pullnotifier.com.